All About Deepseek 2025.03.22 조회7회
This makes Deepseek a great alternative for developers and researchers who want to customize the AI to go well with their wants. The company reportedly aggressively recruits doctorate AI researchers from top Chinese universities. "During training, DeepSeek-R1-Zero naturally emerged with numerous powerful and fascinating reasoning behaviors," the researchers note in the paper. Reasoning models take just a little longer - often seconds to minutes longer - to arrive at solutions compared to a typical non-reasoning model. DeepSeek unveiled its first set of models - DeepSeek Coder, DeepSeek LLM, and DeepSeek Chat - in November 2023. Nevertheless it wasn’t till last spring, when the startup released its subsequent-gen DeepSeek-V2 family of fashions, that the AI business began to take discover. Free DeepSeek v3-R1’s reasoning performance marks an enormous win for the Chinese startup within the US-dominated AI house, particularly as the complete work is open-supply, including how the company trained the entire thing. Chinese AI startup DeepSeek, identified for challenging main AI distributors with open-source technologies, simply dropped one other bombshell: a new open reasoning LLM referred to as DeepSeek-R1. Based on the just lately launched DeepSeek V3 mixture-of-consultants model, DeepSeek-R1 matches the performance of o1, OpenAI’s frontier reasoning LLM, throughout math, coding and reasoning duties. In line with the paper describing the analysis, DeepSeek-R1 was developed as an enhanced model of DeepSeek-R1-Zero - a breakthrough mannequin skilled solely from reinforcement studying.
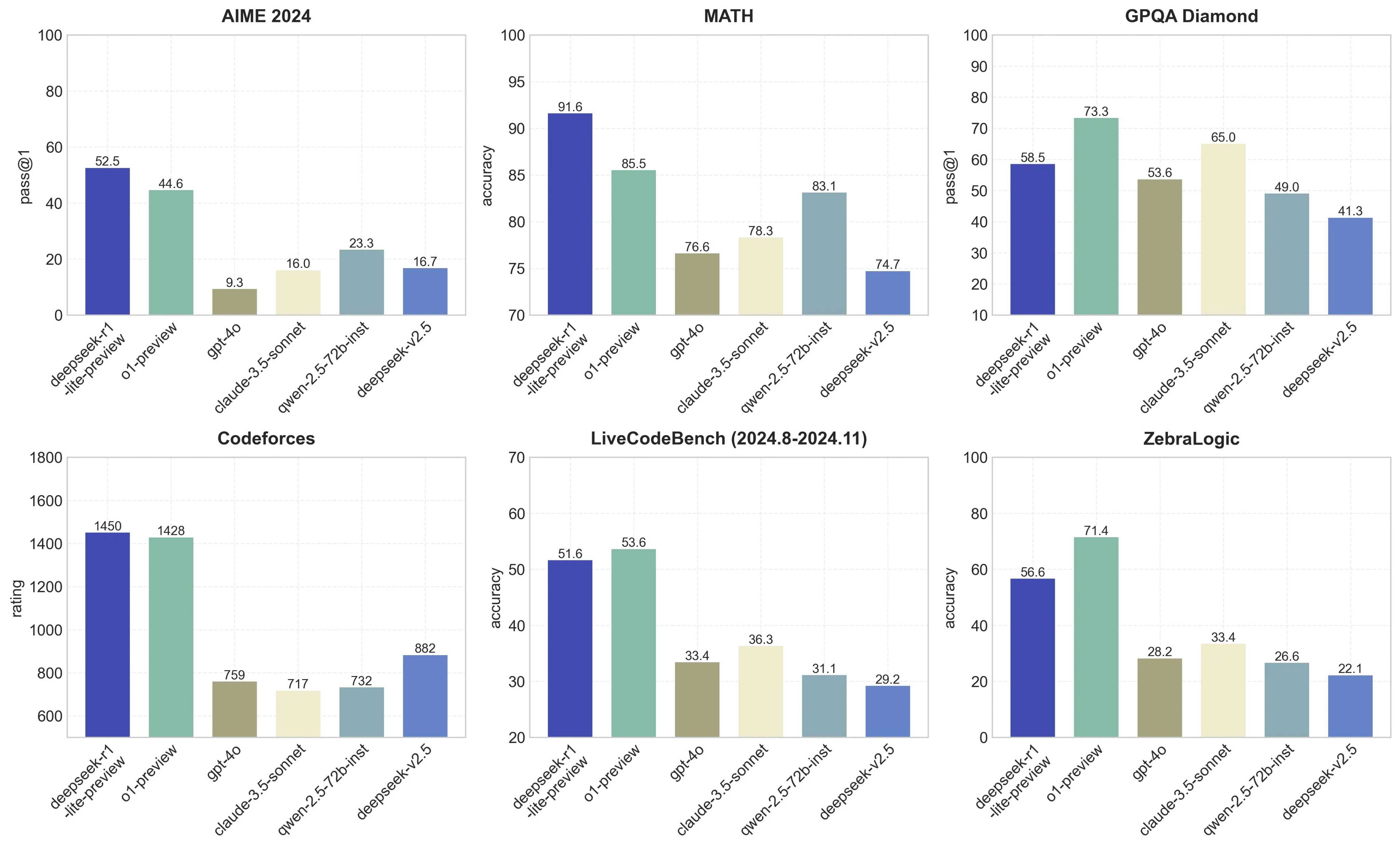
To fix this, the corporate constructed on the work finished for R1-Zero, utilizing a multi-stage strategy combining both supervised learning and reinforcement learning, and thus came up with the enhanced R1 model. Through RL (reinforcement studying, or reward-driven optimization), o1 learns to hone its chain of thought and refine the strategies it makes use of - finally studying to acknowledge and proper its mistakes, or strive new approaches when the present ones aren’t working. First a little back story: After we saw the beginning of Co-pilot quite a bit of different competitors have come onto the display screen merchandise like Supermaven, cursor, and so on. Once i first saw this I instantly thought what if I may make it faster by not going over the network? Developed intrinsically from the work, this capability ensures the model can solve increasingly advanced reasoning duties by leveraging extended check-time computation to explore and refine its thought processes in larger depth. "After thousands of RL steps, DeepSeek-R1-Zero exhibits tremendous efficiency on reasoning benchmarks. In distinction, o1-1217 scored 79.2%, 96.4% and 96.6% respectively on these benchmarks. When tested, DeepSeek-R1 scored 79.8% on AIME 2024 mathematics exams and 97.3% on MATH-500. It also scored 84.1% on the GSM8K mathematics dataset with out high quality-tuning, exhibiting remarkable prowess in fixing mathematical issues.
 To show the prowess of its work, DeepSeek also used R1 to distill six Llama and Qwen models, taking their efficiency to new levels. After wonderful-tuning with the new knowledge, the checkpoint undergoes an extra RL course of, making an allowance for prompts from all situations. Now, continuing the work on this path, DeepSeek has released DeepSeek-R1, which uses a combination of RL and supervised nice-tuning to handle advanced reasoning duties and match the efficiency of o1. Alibaba (BABA) unveils its new artificial intelligence (AI) reasoning mannequin, QwQ-32B, stating it could rival DeepSeek's personal AI whereas outperforming OpenAI's lower-price mannequin. It showcases that open models are additional closing the gap with closed industrial models within the race to synthetic basic intelligence (AGI). AI race and whether the demand for AI chips will sustain. If we choose to compete we can still win, and, if we do, we may have a Chinese company to thank.
To show the prowess of its work, DeepSeek also used R1 to distill six Llama and Qwen models, taking their efficiency to new levels. After wonderful-tuning with the new knowledge, the checkpoint undergoes an extra RL course of, making an allowance for prompts from all situations. Now, continuing the work on this path, DeepSeek has released DeepSeek-R1, which uses a combination of RL and supervised nice-tuning to handle advanced reasoning duties and match the efficiency of o1. Alibaba (BABA) unveils its new artificial intelligence (AI) reasoning mannequin, QwQ-32B, stating it could rival DeepSeek's personal AI whereas outperforming OpenAI's lower-price mannequin. It showcases that open models are additional closing the gap with closed industrial models within the race to synthetic basic intelligence (AGI). AI race and whether the demand for AI chips will sustain. If we choose to compete we can still win, and, if we do, we may have a Chinese company to thank.
The corporate says its models are on a par with or higher than merchandise developed within the United States and are produced at a fraction of the cost. It additionally achieved a 2,029 score on Codeforces - higher than 96.3% of human programmers. DeepSeek additionally hires individuals with none pc science background to help its tech higher perceive a variety of topics, per The new York Times. For Go, every executed linear management-stream code vary counts as one coated entity, with branches associated with one range. Its intuitive graphical interface enables you to build complex automations effortlessly and explore a wide range of n8n integrations to reinforce your current systems with none coding. This underscores the sturdy capabilities of DeepSeek-V3, especially in coping with complex prompts, including coding and debugging tasks. Concerns about AI Coding assistants. Plenty of groups are doubling down on enhancing models’ reasoning capabilities. Lawyers. The trace is so verbose that it totally uncovers any bias, and offers lawyers so much to work with to determine if a mannequin used some questionable path of reasoning.